
Network Topics
The Network Topic Model 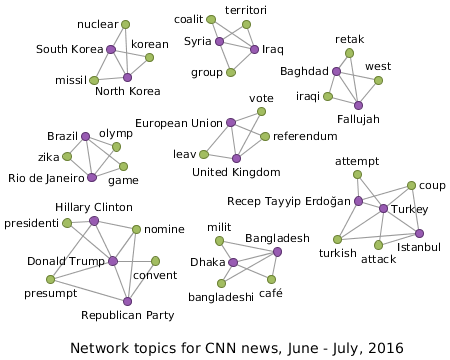
In the analysis and exploration of document collections, topic models serve to classify and cluster documents based on shared content. Traditional topics models, such as those based on Latent Dirichlet allocation (LDA), typically employ graphical models and model topics as (ranked) lists of words from the underlying document collection. In turn, documents are then assigned probability scores for each topic to represent the distribution of content among the documents. However, despite the popularity of graphical models for topic extraction, they face problems in the exploration and correlation of the (often unknown number of) topics extracted from a document collection. Especially in the analysis of large collections of news articles from heterogeneous sources, an intuitive exploration of topics is often difficult. Furthermore, due to the computational complexity of graphical models, the number of topics that can be extracted is limited even before their evolution over time is considered.
With entity-centric network topics, we present a novel framework for exploring evolving corpora of news articles in terms of the topics that are covered over time and the entities that these topics are focused on. Our approach is based on implicit networks, which represent the cooccurrences of entities and terms in the documents as weighted edges. Since edges with high weight between entities are indicative of topics, this allows us to incrementally grow the network substructures around an initial seed edge to explore the context of a topic. Due to the underlying graph structure, the visual representation is more intuitive then lists of terms and easier to expand on the fly as the data is explored. Since such an exploration of topics corresponds to local operations in the network, the approach supports a fully interactive analysis of the news articles that does not require re-computing if the number of topics changes. Furthermore, adding new news articles to the collection simply updates the network and thus avoids expensive recomputations of term and topic distributions, which is necessary a any real-time application.
For further details, we refer to the original publication. In the following, we provide the used data and code of our approach. Furthermore, we recently added a browser-based online interface called TopExNet that can be used to browse and explore network topics in a collection of English news articles from May 2016 to November 2016 (TopExNet demonstration).
News Article Network Data
The used entity-centric implicit network data set is extracted from a set of English news articles from the outlets CNN, LA Times, NY Times, USA Today, CBS News, The Washington Post, IBTimes, BBC, The Independent, Reuters, SkyNews, The Telegraph, The Guardian, and Sidney Morning Herald with a focus on political news between June 1, 2016 and November 30, 2016. It contains 27.7k locations, 72.0k actors, 19.6k organizations, and 329k terms, which are connected by 10.6M distinct edges, from 127,485 news articles. Note that article contents are not contained but article source URLs are provided. The data is distributed over three tab-separated files.news_articles.tsv
Format: <id> <outlet> <date> <url> <title>
- <id>: integer ID of the article in the data set
- <outlet>: label of the news outlet
- <date>: publication date of the article
- <url>: URL of the article
- <title>: plain text title of the article
Format: <id1> <id2> <type1> <type2> <date> <articleID> <outlet> <senDist>
- <id1>: integer ID of the first entity of the edge
- <id2>: integer ID of the second entity of the edge
- <type1>: entity type of the first entity {L, A, O, T}
- <type2>: entity type of the first entity {L, A, O, T}
- <date>: date of publication of the article in which this edge occurs
- <articleID>: integer ID of the article in which this edge occurs
- <outlet>: news outlet of the article in which this edge occurs
- <senDist>: distance (in sentences) between the two entities
Format: <id> <type> <wiki> <label>
- <id>: integer ID of the entity
- <type>: entity type of the entity {L, A, O, T}
- <wiki>: Wikidata ID of the entity (empty if type = T)
- <label>: label of the entity
[zip] Download network data (181 MB compressed, 2.4 GB uncompressed)
Implementation & Code
The preparatory NLP pipeline includes some established tools that we do not provide here. Named entities in the text of the news articles were annotated with Ambiverse and classified according to the YAGO taxonomy (entities of type location, organization, or person). For sentence splitting and parts-of-speech recognition, we used the Stanford POS tagger. The implicit network representation on top of which we realized the topic exploration is adapted from the LOAD network extraction code. The output of all preprocessing steps is contained in the data set described above.The extraction and exploration of entity-based network topics is implemented in the statistical programming framework R. A Github repository is in preparation. In the meantime, all used code is available as an archive.
[zip] Download R implementation of network topic extraction, exploration, and evaluation.
Publications & References
The paper that describes the model will be presented at ECIR '18. If you use either the method or the data, please consider citing us as:
- Andreas Spitz and Michael Gertz.
Entity-centric Topic Extraction and Exploration: A Network-based Approach.
In: Advances in Information Retrieval - 40th European Conference on IR Research, (ECIR 2018), Grenoble, France, March 26-29, 2018
[pdf] [springer] [bibtex] [slides] - Andreas Spitz, Satya Almasian, and Michael Gertz.
TopExNet: Entity-centric Network Topic Exploration in News Streams.
In: Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining (WSDM'19), Melbourne, VIC, Australia, February 11-15. 2019
[pdf] [acm] [bibtex] [poster] [demo]